

Amazon Launches New System for De-identifying Medical Images
Amazon has announced that it has developed a new system that allows identifying protected health information contained in medical images to be automatically removed to prevent patients from being identified from the images.
Medical images often have patients’ protected health information stored as text within the image, including the patient’s name, date of birth, age, and other metrics. Prior to the images being used for research, authorization must be obtained from the patient or all identifying data must be permanently removed. Removing PHI from images requires a manual check and alteration of the image to redact the PHI and that can be an expensive and time-consuming process, especially when large number of images must be de-identified.
The new system uses Amazon’s Rekognition machine-learning service, which can detect and extract text from images. The text is then fed through Amazon Comprehend Medical to identify any PHI. In combination with Python code it is possible to quickly redact any PHI in the images. The system works on PNG, JPEG, and DICOM images.
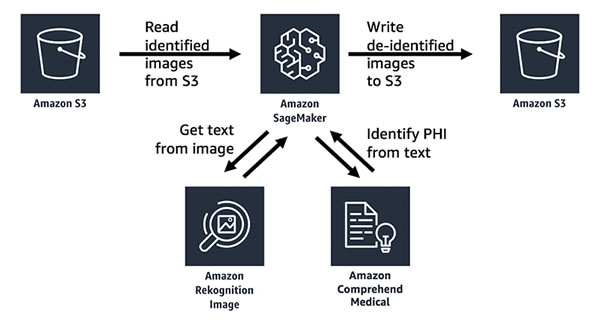
A confidence score is provided by the service which indicates the level of confidence in the accuracy of the detected entity, which can form the basis of reviews to make sure that information has been correctly identified. The desired confidence level – from 0.00 to 1.00 – can be set by the user. A confidence level of 0.00 will see all text identified by the service be redacted.
Get The FREE
HIPAA Compliance Checklist
Immediate Delivery of Checklist Link To Your Email Address
Please Enter Correct Email Address
Your Privacy Respected
HIPAA Journal Privacy Policy

Amazon says the system allows healthcare organizations to de-identify large numbers of images quickly and inexpensively. Amazon notes that the system can be used to batch process thousands or millions of images. Also, once an image has been processed and the location of PHI has been identified, it is possible to associate a Lambda function to automatically redact PHI from any new images when they are uploaded to an Amazon S3 bucket.
